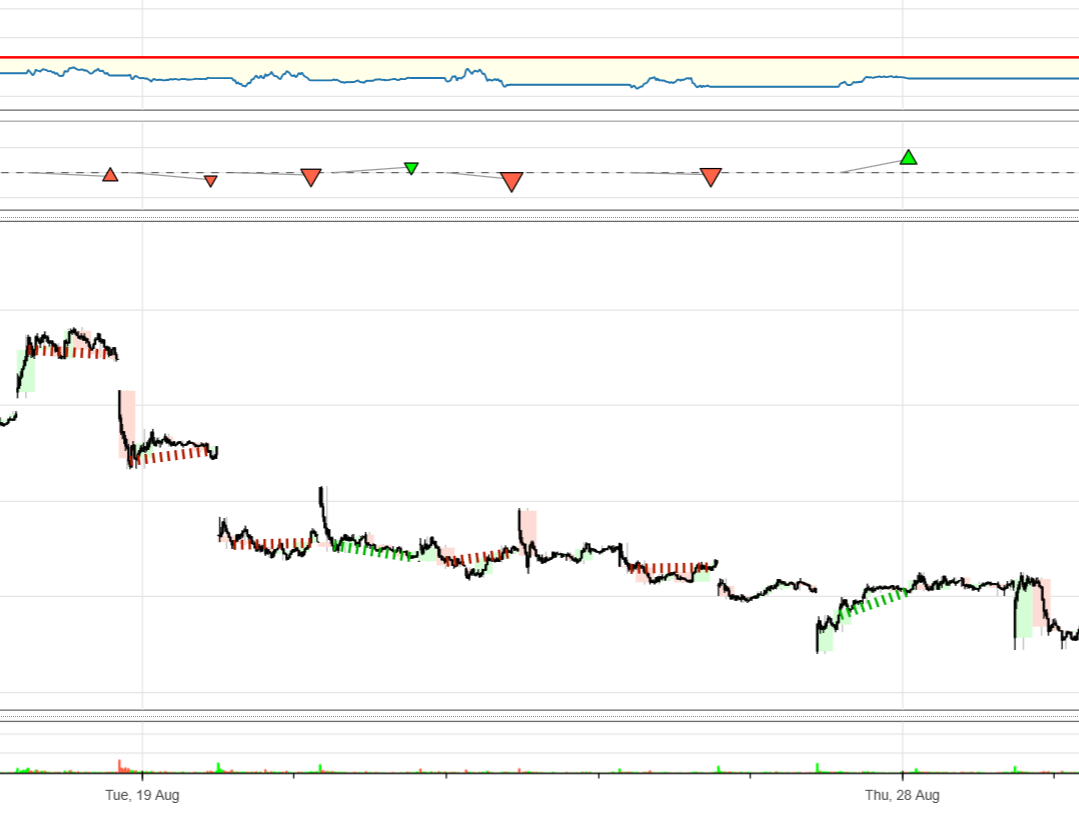
前回は30分ブレークアウト戦略で買い(ロング)のみでバックテストやった。その結果がこれ。
11銘柄中、8銘柄で勝ち、3銘柄で負け、トータル勝ち。資金は100万円。イビデンでリターンが5.7%ということは57000円の利確となる。
期間は60日。そのうちトレードは各銘柄30日くらいなので、半分しかトレードしてない。
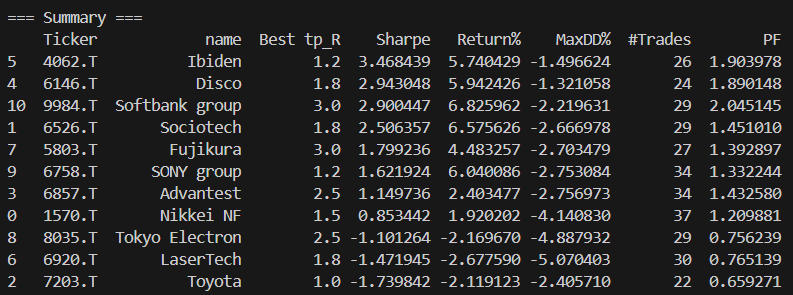
株価が下がっている日は空売り(ショート)すればトレード回数が倍になって利確も倍になるのではないかと考えて、ショートもできるようにChatGPTにソースを変更してもらった。
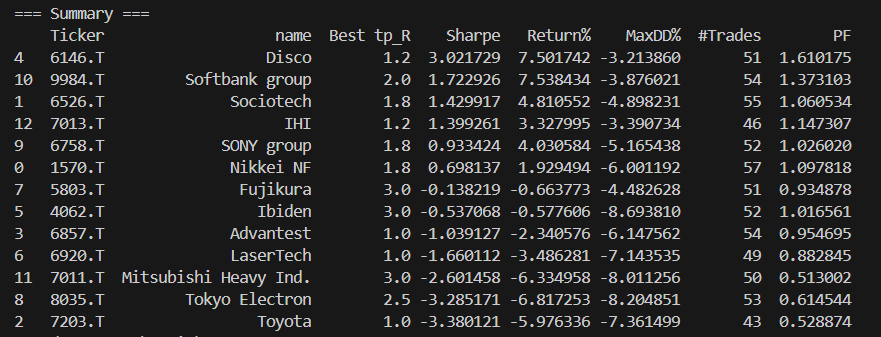
取引回数は倍くらいに増えて、リターンが増えた銘柄もあるけど、負け銘柄が増えて、トータルでプラマイゼロみたいな結果になった。これは予想外。ドテンは往復ビンタをくらうだけなのでやってはいけないのかな。確かに実トレードでも、空売りで入って負けて、今日は上昇トレンドかと思って買うと天井で往復ビンタをくらう。バックテストもドテンは負ける結果になった。
OpeningRangeBreakout_30m__Optimize-short.py
import yfinance as yf
import pandas as pd
from backtesting import Backtest, Strategy
from datetime import datetime, time, timedelta
import pytz
#import multiprocessing as mp
#import backtesting as btlib # pip: Backtesting.py
# =============================
# 30分ブレークアウト(ORBO 30m)
# =============================
# 概要:
# ・市場オープン(09:00)〜09:30の高値・安値を Opening Range(OR) とする
# ・09:30以降、上抜けでロング(ORHブレイク)。ストップは ORL。任意でTP=R倍
# ・同日中は 1 回の新規のみ(デフォルト)。約定は Backtesting.py 仕様で次バー寄り。
# ・資金上限クリップ/未約定抑制/立ち上がり検出を実装
#
# 使い方:
# python OpeningRangeBreakout_30m.py (スクリプト単体実行)
# 下の __main__ の設定を必要に応じて変更
#
# 依存:
# pip install yfinance backtesting pandas pytz
JST = "Asia/Tokyo"
# 1) Windowsの並列最適化は spawn 前提
#btlib.Pool = mp.get_context("spawn").Pool
class ORB30(Strategy):
# === パラメータ ===
MARKET_OPEN = time(9, 0) # 東証オープン
OR_MINUTES = 30 # オープニングレンジの分数
NO_NEW_AFTER = time(14, 30) # この時刻以降は新規を出さない
use_fixed_size = False # True: 固定枚数で発注 / False: リスク一定
fixed_size = 100 # 固定発注サイズ
risk_per_trade = 0.01 # 口座の1%を1トレードの最大リスクに
tp_R = 1.5 # 利確は R=1.5 倍(0 なら TP なし)
one_entry_per_day = True # 同日中は1回のみエントリー
eod_flatten = True # 引け前に必ず手仕舞い
eod_close_time = time(14, 55) # 例: 14:55でクローズ
# === 内部状態 ===
def init(self):
self.current_day = None
self.orh = None
self.orl = None
self.or_ready = False
self.entry_done_today = False
self.entry_ok_prev = False
self.last_entry_bar = -999999
# ログ用
self.afford_clip = 0 # 資金クリップ回数
self.afford_block = 0 # 資金不足で size<1 になりブロック回数
# VWAP 累積用(その日ごとにリセット)
self._cum_pv = 0.0 # 累積(価格×出来高)
self._cum_vol = 0.0 # 累積出来高
def _jst_dt(self):
ts = pd.Timestamp(self.data.index[-1])
if ts.tzinfo is None:
return ts.tz_localize(JST)
return ts.tz_convert(JST)
def _time_of_day(self):
return self._jst_dt().time()
def _date(self):
return self._jst_dt().date()
def _within_or_window(self, t: time) -> bool:
start = self.MARKET_OPEN
end = (datetime.combine(datetime.today(), start) +
timedelta(minutes=self.OR_MINUTES)).time()
return start <= t < end
def _after_or_window(self, t: time) -> bool:
start = self.MARKET_OPEN
end = (datetime.combine(datetime.today(), start) +
timedelta(minutes=self.OR_MINUTES)).time()
return t >= end
def next(self):
t = self._time_of_day()
d = self._date()
# if not hasattr(self, "_dbg"):
# self._dbg = 0
# if self._dbg < 6: # 最初の数回だけ出力
# print("[DBG] t,d:", t, d, "| orh,orl:", self.orh, self.orl, "| or_ready:", self.or_ready)
# self._dbg += 1
close = float(self.data.Close[-1])
high = float(self.data.High[-1])
low = float(self.data.Low[-1])
vol = float(self.data.Volume[-1])
# === 日替わり初期化 ===
if self.current_day != d:
self.current_day = d
self.orh = None; self.orl = None; self.or_ready = False
self.entry_done_today = False
self.entry_ok_prev = False
self.last_entry_bar = -999999
self._cum_pv = 0.0
self._cum_vol = 0.0
if self.position:
self.position.close()
return
# === OR構築(オープニングレンジ内) ===
if self._within_or_window(t):
self.orh = high if (self.orh is None or high > self.orh) else self.orh
self.orl = low if (self.orl is None or low < self.orl) else self.orl
self.or_ready = False
if vol > 0:
self._cum_pv += close * vol
self._cum_vol += vol
return
# OR確定(ウィンドウ終了後に一度だけ)
if (not self.or_ready) and (self.orh is not None) and (self.orl is not None) and self._after_or_window(t):
self.or_ready = True
# === VWAP更新(場中毎バー) ===
if vol > 0:
self._cum_pv += close * vol
self._cum_vol += vol
vwap_now = self._cum_pv / max(self._cum_vol, 1e-9)
# === デイトレ:引け前に必ずクローズ(最優先) ===
if self.position and self.eod_flatten and t >= self.eod_close_time:
self.position.close()
return
# 既存ポジ保有中は新規を出さない(EODクローズは上で済ませる)
# if self.position:
# return
# 新規発注の共通ガード
if not self.or_ready:
return
if t >= self.NO_NEW_AFTER:
return
if self.one_entry_per_day and self.entry_done_today:
return
# === エントリー条件(VWAPコンファーム付き) ===
long_ok = (close > self.orh) and (close > vwap_now) if (self.orh is not None) else False
short_ok = (close < self.orl) and (close < vwap_now) if (self.orl is not None) else False
entry_ok = long_ok or short_ok
# 立ち上がりだけ許可
edge = entry_ok and (not self.entry_ok_prev)
self.entry_ok_prev = entry_ok
if not edge or self.orders:
return
# === リスク定義・SL/TP(方向別) ===
if long_ok:
risk = max(close - self.orl, 1e-6)
sl = self.orl
tp = close + self.tp_R * (close - sl) if self.tp_R > 0 else None
side = self.buy
else:
risk = max(self.orh - close, 1e-6)
sl = self.orh
tp = close - self.tp_R * (sl - close) if self.tp_R > 0 else None
side = self.sell
# === サイジング(資金上限クリップ付き) ===
if self.use_fixed_size:
size = int(self.fixed_size)
else:
size = int((self.equity * self.risk_per_trade) / risk)
size = max(1, size)
max_affordable = int(self.equity // max(close, 1e-9))
if max_affordable <= 0:
self.afford_block += 1
return
if size > max_affordable:
self.afford_clip += 1
size = max_affordable
# === 発注 ===
if tp is not None:
side(size=size, sl=sl, tp=tp)
else:
side(size=size, sl=sl)
self.entry_done_today = True
# =============================
# データ取得 & バックテスト実行
# =============================
def load_data(ticker: str = "7203.T", period: str = "60d", interval: str = "5m") -> pd.DataFrame:
"""
yfinance の列体系(単一/二重)に頑強に対応し、
Backtesting.py が期待する単一レベルの ['Open','High','Low','Close','Volume'] 列へ正規化する。
さらに空データや重複インデックスも整える。
"""
df = yf.download(
ticker,
period=period,
interval=interval,
auto_adjust=False,
actions=False,
group_by="column", # 可能なら単一列
progress=False,
)
if df is None or len(df) == 0:
raise ValueError("No data returned from yfinance. Try a shorter 'period' or different 'interval'.")
# --- 列正規化 ---
def _ensure_ohlcv_columns(_df: pd.DataFrame) -> pd.DataFrame:
# すでに単一レベルで Open などが揃っているならそのまま
base = {"Open", "High", "Low", "Close"}
if not isinstance(_df.columns, pd.MultiIndex):
cols = set(map(str, _df.columns))
# 小文字化対応
if base.issubset(cols):
return _df
if base.issubset({c.capitalize() for c in cols}):
_df.columns = [c.capitalize() for c in _df.columns]
return _df
# MultiIndex の場合:OHLCV が level=0 にいるケースが多い
if isinstance(_df.columns, pd.MultiIndex):
lv0 = list(map(str, _df.columns.get_level_values(0)))
lv1 = list(map(str, _df.columns.get_level_values(1)))
if base.issubset(set(lv0)):
_df.columns = _df.columns.get_level_values(0)
return _df
if base.issubset(set(lv1)):
_df.columns = _df.columns.get_level_values(1)
return _df
# それでもダメなら、各タプルの先頭を採用
try:
_df.columns = [t[0] if isinstance(t, tuple) and len(t) > 0 else str(t) for t in _df.columns]
return _df
except Exception:
pass
return _df
df = _ensure_ohlcv_columns(df)
# 余計な列を落とし、欠けている列がないか検証
keep = ["Open", "High", "Low", "Close", "Volume"]
# Volume が存在しない市場/足でも動くように、まずは可能な列だけ選択
present = [c for c in keep if c in df.columns]
df = df[present].copy()
# Open/High/Low/Close が揃っているか最終確認
required = {"Open", "High", "Low", "Close"}
if not required.issubset(set(df.columns)):
raise ValueError(f"Columns after normalization: {list(df.columns)} — Missing one of {sorted(required)}")
# 欠損・重複・順序
df = df.dropna()
if df.index.has_duplicates:
df = df[~df.index.duplicated(keep='last')]
df = df.sort_index()
return df
def normalize_heatmap(hm):
"""Backtesting.pyの版差対策:SeriesでもDataFrameでもtp_Rとmetricを取り出す"""
if hm is None:
return None, None
if isinstance(hm, pd.Series):
metric = hm.name or "Sharpe Ratio"
df = hm.rename(metric).reset_index()
df.columns = ['tp_R', metric]
return df, metric
# DataFrame
metric_candidates = [c for c in hm.columns
if c.lower().replace(' ','') in ('sharperatio','sharpe')]
metric = metric_candidates[0] if metric_candidates else hm.columns[-1]
df = hm.reset_index()
if 'tp_R' not in df.columns and df.index.name:
df = df.rename(columns={df.index.name: 'tp_R'})
return df, metric
brand_names = {
"1570.T": "Nikkei NF",
"6526.T": "Sociotech",
"7203.T": "Toyota",
"6857.T": "Advantest",
"6146.T": "Disco",
"4062.T": "Ibiden",
"6920.T": "LaserTech",
"5803.T": "Fujikura",
"8035.T": "Tokyo Electron",
"6758.T": "SONY group",
"9984.T": "Softbank group",
"7011.T": "Mitsubishi Heavy Ind.",
"7013.T": "IHI",
# "AAPL": "Apple Inc.",
}
PERIOD = "60d"
INTERVAL = "5m"
param_grid = [1.0, 1.2, 1.5, 1.8, 2.0, 2.5, 3.0] # tp_R 候補
summary_rows = []
for tk,name in brand_names.items():
print(f"\n=== {tk} {name} ===")
try:
df = load_data(tk, PERIOD, INTERVAL)
bt = Backtest(df, ORB30, cash=1_000_000, commission=0.0005, exclusive_orders=True)
# 最適化(Sharpe基準を例に)
res = bt.optimize(
tp_R=param_grid,
maximize='Sharpe Ratio',
constraint=lambda p: p.tp_R > 0,
return_heatmap=True
)
stats, heatmap = res if isinstance(res, tuple) else (res, None)
best_tp = stats._strategy.tp_R
# 全試行の表を整形して保存
hm_df, metric_col = normalize_heatmap(heatmap)
if hm_df is not None:
hm_df.sort_values(metric_col, ascending=False).to_csv(f"{tk}_opt_heatmap.csv", index=False,float_format="%.6f")
# ベスト設定の詳細
best_trades = stats['_trades']
best_trades.to_csv(f"{tk}_trades_best.csv", index=False)
# ベスト設定で再実行→プロット保存(GUI不要)
_ = bt.run(tp_R=best_tp)
bt.plot(filename=f"{tk}_orb30_best.html", open_browser=False)
# 要点をサマリー行に
summary_rows.append({
"Ticker": tk,
"name":name,
"Best tp_R": best_tp,
"Sharpe": stats.get('Sharpe Ratio', None),
"Return%": stats.get('Return [%]', None),
"MaxDD%": stats.get('Max. Drawdown [%]', None),
"#Trades": stats.get('# Trades', None),
"PF": stats.get('Profit Factor', None)
})
print(f" -> Best tp_R={best_tp}, Sharpe={stats.get('Sharpe Ratio')}, Return%={stats.get('Return [%]')}")
print(f" Saved: {tk}_opt_heatmap.csv, {tk}_trades_best.csv, {tk}_orb30_best.html")
except Exception as e:
print(f" [ERROR] {tk}: {e}")
# 銘柄横断サマリー
summary = pd.DataFrame(summary_rows)
summary = summary.sort_values("Sharpe", ascending=False)
print("\n=== Summary ===")
print(summary)
summary.to_csv("summary_by_ticker.csv", index=False)
print("Saved summary_by_ticker.csv")
コメント