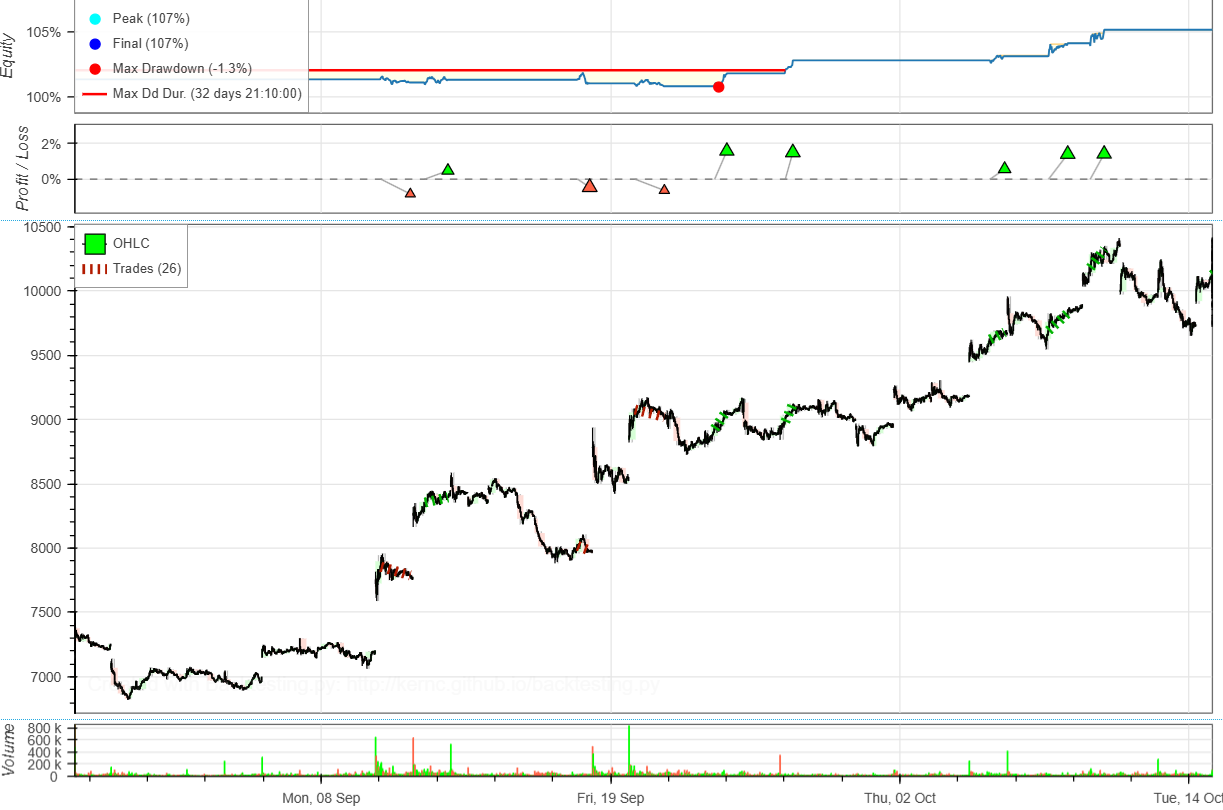
30分ブレークアウト戦略とは、寄り付き後30分の最高値を超えたらロング、最安値を下回ったらショートという単純な戦略。手動デイトレだとそもそも30分も待てずにすぐポジションを取ってしまって負けることが多い。
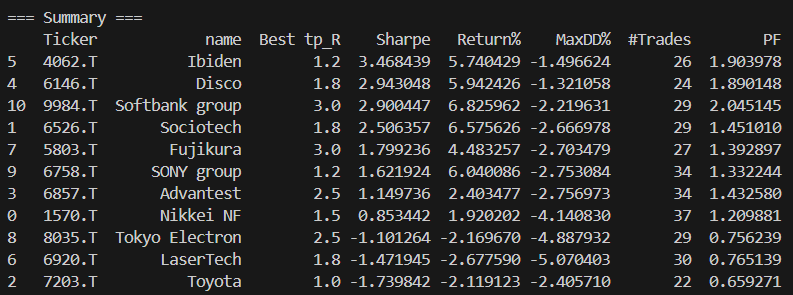
まずトヨタでバックテストやってみた。全然勝てない。やっぱりこんな単純な戦法では勝てないんだと思って、いくつかの銘柄でやってみてびっくり。プラスの銘柄の方が多い。特にイビデンのシャープレシオが高い。トヨタは実トレードでも勝てないけど、バックテストでも勝てない。トヨタは難しいのかもしれない。手を出してはいけない銘柄であることをこのバックテストは示しているのかも。今回試してみた銘柄は値嵩株ばっかりでデイトレできないけど、手ごろな価格としてソシオネクストがバックテストで勝ってる。ORD30m戦略ではないけど実トレードでソシオネクストは負け続けているから、バックテストがどれだけ信頼できるかいつか実トレードでORD30m戦略を試してみたい。
OpeningRangeBreakout_30m_optimize.py(現時点でロングのみ)
/
import yfinance as yf
import pandas as pd
from backtesting import Backtest, Strategy
from datetime import datetime, time, timedelta
import pytz
# =============================
# 30分ブレークアウト(ORBO 30m)
# =============================
# 概要:
# ・市場オープン(09:00)〜09:30の高値・安値を Opening Range(OR) とする
# ・09:30以降、上抜けでロング(ORHブレイク)。ストップは ORL。任意でTP=R倍
# ・同日中は 1 回の新規のみ(デフォルト)。約定は Backtesting.py 仕様で次バー寄り。
# ・資金上限クリップ/未約定抑制/立ち上がり検出を実装
#
# 使い方:
# python OpeningRangeBreakout_30m.py (スクリプト単体実行)
# 下の __main__ の設定を必要に応じて変更
#
# 依存:
# pip install yfinance backtesting pandas pytz
JST = pytz.timezone("Asia/Tokyo")
class ORB30(Strategy):
# === パラメータ ===
MARKET_OPEN = time(9, 0) # 東証オープン
OR_MINUTES = 30 # オープニングレンジの分数
NO_NEW_AFTER = time(14, 30) # この時刻以降は新規を出さない
use_fixed_size = False # True: 固定枚数で発注 / False: リスク一定
fixed_size = 100 # 固定発注サイズ
risk_per_trade = 0.01 # 口座の1%を1トレードの最大リスクに
tp_R = 1.5 # 利確は R=1.5 倍(0 なら TP なし)
one_entry_per_day = True # 同日中は1回のみエントリー
eod_flatten = True # 引け前に必ず手仕舞い
eod_close_time = time(14, 55) # 例: 14:55でクローズ
# === 内部状態 ===
def init(self):
self.current_day = None
self.orh = None
self.orl = None
self.or_ready = False
self.entry_done_today = False
self.entry_ok_prev = False
self.last_entry_bar = -999999
# ログ用
self.afford_clip = 0 # 資金クリップ回数
self.afford_block = 0 # 資金不足で size<1 になりブロック回数
# ユーティリティ: 現在バーのJSTローカル時刻
def _jst_dt(self):
# Backtesting は pandas の index をそのまま保持
# self.data.index[-1] は tz-naive のことがあるので、強制的にJSTとして扱う
idx = self.data.index[-1]
if isinstance(idx, pd.Timestamp):
if idx.tzinfo is None:
return idx.tz_localize(JST)
return idx.tz_convert(JST)
# 念の為
return pd.Timestamp(idx).tz_localize(JST)
def _time_of_day(self):
return self._jst_dt().time()
def _date(self):
return self._jst_dt().date()
def _within_or_window(self, t: time) -> bool:
# 09:00 <= t < 09:30
start = self.MARKET_OPEN
end = (datetime.combine(datetime.today(), start) + timedelta(minutes=self.OR_MINUTES)).time()
return (t >= start) and (t < end)
def _after_or_window(self, t: time) -> bool:
start = self.MARKET_OPEN
end = (datetime.combine(datetime.today(), start) + timedelta(minutes=self.OR_MINUTES)).time()
return t >= end
def next(self):
t = self._time_of_day()
d = self._date()
# === 日付が変わったら初期化 ===
if self.current_day != d:
self.current_day = d
self.orh = None
self.orl = None
self.or_ready = False
self.entry_done_today = False
# 念のための安全装置(万一、前日から持ち越していたら即手仕舞い)
if self.position:
self.position.close()
return
price = float(self.data.Close[-1])
high = float(self.data.High[-1])
low = float(self.data.Low[-1])
# === OR 構築 ===
if self._within_or_window(t):
if self.orh is None or high > self.orh:
self.orh = high
if self.orl is None or low < self.orl:
self.orl = low
self.or_ready = False
return # OR 構築中は発注しない
# OR 完了フラグ
if (not self.or_ready) and (self.orh is not None) and (self.orl is not None) and self._after_or_window(t):
self.or_ready = True
# === 既存ポジの管理(SL/TP は発注時に指定するのでここでは何もしない) ===
# if self.position:
# return
# 2) デイトレ化の核心:引け前に必ずクローズ
if self.position and self.eod_flatten and t >= self.eod_close_time:
self.position.close()
return
# === 新規エントリー ===
# 時間制限
if t >= self.NO_NEW_AFTER:
return
if not self.or_ready:
return
if self.one_entry_per_day and self.entry_done_today:
return
# エントリー条件(上抜け): 現バー終値で ORH を越えて確定
entry_ok = (self.data.Close[-1] > self.orh)
# 立ち上がり検出(連続真の連打を防ぐ)
edge = entry_ok and (not self.entry_ok_prev)
self.entry_ok_prev = entry_ok
if not edge:
return
# 未約定の重複を抑制
if self.orders:
return
# --- サイジング ---
# リスク = 現在価格 - ORL(逆行したら損切り)
risk = max(price - self.orl, 1e-6)
if self.use_fixed_size:
size = int(self.fixed_size)
else:
size = int((self.equity * self.risk_per_trade) / risk)
if size < 1:
size = 1
# 資金上限クリップ(現物前提 / 手数料は考慮外)
max_affordable = int(self.equity // max(price, 1e-9))
if size > max_affordable:
self.afford_clip += 1
size = max_affordable
if size < 1:
self.afford_block += 1
return
# SL/TP 設定
sl_price = self.orl # ORL で損切り
if self.tp_R and self.tp_R > 0:
tp_price = price + self.tp_R * (price - sl_price)
else:
tp_price = None
# 発注
if tp_price is not None:
self.buy(size=size, sl=sl_price, tp=tp_price)
else:
self.buy(size=size, sl=sl_price)
self.entry_done_today = True
# =============================
# データ取得 & バックテスト実行
# =============================
def load_data(ticker: str = "7203.T", period: str = "60d", interval: str = "5m") -> pd.DataFrame:
"""
yfinance の列体系(単一/二重)に頑強に対応し、
Backtesting.py が期待する単一レベルの ['Open','High','Low','Close','Volume'] 列へ正規化する。
さらに空データや重複インデックスも整える。
"""
df = yf.download(
ticker,
period=period,
interval=interval,
auto_adjust=False,
actions=False,
group_by="column", # 可能なら単一列
progress=False,
)
if df is None or len(df) == 0:
raise ValueError("No data returned from yfinance. Try a shorter 'period' or different 'interval'.")
# --- 列正規化 ---
def _ensure_ohlcv_columns(_df: pd.DataFrame) -> pd.DataFrame:
# すでに単一レベルで Open などが揃っているならそのまま
base = {"Open", "High", "Low", "Close"}
if not isinstance(_df.columns, pd.MultiIndex):
cols = set(map(str, _df.columns))
# 小文字化対応
if base.issubset(cols):
return _df
if base.issubset({c.capitalize() for c in cols}):
_df.columns = [c.capitalize() for c in _df.columns]
return _df
# MultiIndex の場合:OHLCV が level=0 にいるケースが多い
if isinstance(_df.columns, pd.MultiIndex):
lv0 = list(map(str, _df.columns.get_level_values(0)))
lv1 = list(map(str, _df.columns.get_level_values(1)))
if base.issubset(set(lv0)):
_df.columns = _df.columns.get_level_values(0)
return _df
if base.issubset(set(lv1)):
_df.columns = _df.columns.get_level_values(1)
return _df
# それでもダメなら、各タプルの先頭を採用
try:
_df.columns = [t[0] if isinstance(t, tuple) and len(t) > 0 else str(t) for t in _df.columns]
return _df
except Exception:
pass
return _df
df = _ensure_ohlcv_columns(df)
# 余計な列を落とし、欠けている列がないか検証
keep = ["Open", "High", "Low", "Close", "Volume"]
# Volume が存在しない市場/足でも動くように、まずは可能な列だけ選択
present = [c for c in keep if c in df.columns]
df = df[present].copy()
# Open/High/Low/Close が揃っているか最終確認
required = {"Open", "High", "Low", "Close"}
if not required.issubset(set(df.columns)):
raise ValueError(f"Columns after normalization: {list(df.columns)} — Missing one of {sorted(required)}")
# 欠損・重複・順序
df = df.dropna()
if df.index.has_duplicates:
df = df[~df.index.duplicated(keep='last')]
df = df.sort_index()
return df
def normalize_heatmap(hm):
"""Backtesting.pyの版差対策:SeriesでもDataFrameでもtp_Rとmetricを取り出す"""
if hm is None:
return None, None
if isinstance(hm, pd.Series):
metric = hm.name or "Sharpe Ratio"
df = hm.rename(metric).reset_index()
df.columns = ['tp_R', metric]
return df, metric
# DataFrame
metric_candidates = [c for c in hm.columns
if c.lower().replace(' ','') in ('sharperatio','sharpe')]
metric = metric_candidates[0] if metric_candidates else hm.columns[-1]
df = hm.reset_index()
if 'tp_R' not in df.columns and df.index.name:
df = df.rename(columns={df.index.name: 'tp_R'})
return df, metric
brand_names = {
"1570.T": "Nikkei NF",
"6526.T": "Sociotech",
"7203.T": "Toyota",
"6857.T": "Advantest",
"6146.T": "Disco",
"4062.T": "Ibiden",
"6920.T": "LaserTech",
"5803.T": "Fujikura",
"8035.T": "Tokyo Electron",
"6758.T": "SONY group",
"9984.T": "Softbank group",
# "AAPL": "Apple Inc.",
}
TICKERS = ["1570.T", "7203.T", "8306.T","6526.T","4062.T","6920.T","5803.T","8035.T","9984.T"]
PERIOD = "60d"
INTERVAL = "5m"
param_grid = [1.0, 1.2, 1.5, 1.8, 2.0, 2.5, 3.0] # tp_R 候補
summary_rows = []
#for tk in TICKERS:
for tk,name in brand_names.items():
print(f"\n=== {tk} {name} ===")
try:
df = load_data(tk, PERIOD, INTERVAL)
bt = Backtest(df, ORB30, cash=1_000_000, commission=0.0005, exclusive_orders=True)
# 最適化(Sharpe基準を例に)
res = bt.optimize(
tp_R=param_grid,
maximize='Sharpe Ratio',
constraint=lambda p: p.tp_R > 0,
return_heatmap=True
)
stats, heatmap = res if isinstance(res, tuple) else (res, None)
best_tp = stats._strategy.tp_R
# 全試行の表を整形して保存
hm_df, metric_col = normalize_heatmap(heatmap)
if hm_df is not None:
hm_df.sort_values(metric_col, ascending=False).to_csv(f"{tk}_opt_heatmap.csv", index=False)
# ベスト設定の詳細
best_trades = stats['_trades']
best_trades.to_csv(f"{tk}_trades_best.csv", index=False)
# ベスト設定で再実行→プロット保存(GUI不要)
_ = bt.run(tp_R=best_tp)
bt.plot(filename=f"{tk}_orb30_best.html", open_browser=False)
# 要点をサマリー行に
summary_rows.append({
"Ticker": tk,
"name":name,
"Best tp_R": best_tp,
"Sharpe": stats.get('Sharpe Ratio', None),
"Return%": stats.get('Return [%]', None),
"MaxDD%": stats.get('Max. Drawdown [%]', None),
"#Trades": stats.get('# Trades', None),
"PF": stats.get('Profit Factor', None)
})
print(f" -> Best tp_R={best_tp}, Sharpe={stats.get('Sharpe Ratio')}, Return%={stats.get('Return [%]')}")
print(f" Saved: {tk}_opt_heatmap.csv, {tk}_trades_best.csv, {tk}_orb30_best.html")
except Exception as e:
print(f" [ERROR] {tk}: {e}")
# 銘柄横断サマリー
summary = pd.DataFrame(summary_rows)
summary = summary.sort_values("Sharpe", ascending=False)
print("\n=== Summary ===")
print(summary)
summary.to_csv("summary_by_ticker.csv", index=False)
print("Saved summary_by_ticker.csv")
ちなみに、デイトレで負け続けて口座のお金が無くなってしまった。新規建て余力がゼロなので1日信用でデイトレできないので、日経NFの現物株1株でトレードしてる。昨日400円負け、今日も400円負け。どちらも逆指値に差さってしまった。
これまでどうしても勝てない銘柄、というか大負けした銘柄に三菱重工があるので、ORB30m戦略をバックテストしてみた。最悪の結果になった。実トレードでORB30戦略をやったことはないけど、デイトレで勝てないのはこういうことなのかね。
Ticker name Best tp_R Sharpe Return% MaxDD% #Trades PF
11 7011.T Mitsubishi Heavy Ind. 3.0 -2.947328 -4.434254 -4.782149 22 0.381313
YouTubeで日経平均が4万4千円のころ売りサインが出ているという動画をいくつも出している人がいたけど、4万4千円が天井だと考える人が多くて空売りが爆増したから、ショートカバーで5万円近くまで上昇したのかな?
以前にもS&P500に売りサインという動画が何個か出たときは確かに下がったけどしばらくしてまた上昇して高値を更新してる。そもそも投資信託って長期投資が前提のはずだと思うのに売りサインが出たから売るというものではないはず。
YouTubeの売りサイン、買いサイン動画に騙されてはいけない。

コメント